Apache Kafka for .NET developers
Apache Kafka became one of those technologies and buzzwords you hear often and looks to be very exotic and cool. Getting started with Apache Kafka as a .Net developer might look daunting and difficult. How do you even install it on a Windows machine? It is not part of a .net world, it's Java and Scala. Even if you are comfortable with Docker you may find not an easy approach. When you google Apache Kafka, most of the top links with documentation or tutorial will explain you a lot about Kafka, the theory how it works and if you're lucky and have enough perseverance you'll get down to the code, mostly Java. In this article will explain the basics of Kafka. It will help you to start with Kafka with no prior knowledge of it. We're going to build a small application in C#. I will present just enough theory about Kafka for you to understand the basics of it, look at some C# code and only after that will explain more about Kafka. We'll run Kafka on Windows Subsystem for Linux (WSL) - in other words, on Linux bash running on Windows, in this way you don't have alter your Windows machine in any way apart from having WSL installed.
Kafka is not a popular tool for .net developers and one of the reasons I think is because .net developers are not very familiars with the tools and environment Kafka runs on. In this article I will try to close the knowledge gap and show how easy it is to run Kafka locally on a windows machine.
What is Apache Kafka
Apache Kafka is a distributes streaming platform. What makes Kafka different from other streaming platform, is the fact that it is very-very fast. It was created and open-sourced by LinkedIn. It is open source, but it is maintained by Confluent - the company founded by original Kafka developers. They offer additional commercial features for Kafka designed to enhance the streaming experience. Apart from being very fast, Kafka has a resilient architecture and it is fault tolerant.
Just enough to get started
I like starting writing code as early as possible when I learn a new technology or language. I will do the same here - I will explain a few basic concept - just enough to understand what's going in code and later will go deeper on these concepts.
Zookeeper - manages Kafka Brokers (Servers)
Topic - it's like a table in database. The topic is defined by its name and you can create as many as you want.
Producer - Producers write data to topics.
Consumers - Consumers read data from a topic.
Kafka setup
In order to run our code, we'll need a working instance of Apache Kafka. We have a few options for a Windows machine. Usually we would run Kafka installation which will install everything you need, including Java. But now in Windows we have WSL.
We're going to run Kafka on Windows Subsystem for Linux (WSL) - in other words, this is a Linux command line (Linux bash) running on a windows machine. If you don't have it installed on your machine yet, go to
https://docs.microsoft.com/en-us/windows/wsl/install-win10 and install it. This article is based on running Ubuntu.
Next we'll install and run Kafka
- Download Kafka from https://kafka.apache.org/quickstart and copy it into a particular folder, for exemple: c:/kafka
- Open WSL command line (linux bash) and switch to Kafka folder from the previous step and un-tar it (replace with your kafka version)
cd /mnt/c/kafka
tar -xzf kafka_2.11-1.1.0.tgz
In the current WSL switch to the extracted kafka folder and run zookeeper app from the bin folder.
bin/zookeeper-server-start.sh config/zookeeper.properties
This will create a broker
Open a new WSL console and switch to kafka folder as in previous steps. Run kafka server:
bin/kafka-server-start.sh config/server.properties
We are ready to create C# producers and consumers but before that, let's inspect kafka. In order to dot that we'll install Kafka Tool http://www.kafkatool.com. Open the application after the installation and provide a name for the cluster. Everything else should stay by default. Add the connection and you can see three folders: Brokers, Topics and Consumers. Play around with the app by expainding the folders on the left hand side and check the settings. It's nice to visualize all the Kafka elements.
We need to create a topic for our C# example. You can create a topic using kafkatool but let's create it from the command line. Open a new bash command and run:
bin/kafka-topics.sh --create --topic blog-topic --zookeeper localhost:2181 --replication-factor 1 --partitions 1
Now we're ready to run our C# example. Download or clone the source code from https://github.com/ralbu/kafka-sample and run it either from Visual Studio which will start both projects or run from dotnet core command line.
You should have both consumer and producer running. When you type in the producer command line and hit enter consumer will pick it up and display the message in its own window.
We've got our example running, now it's time to dig deeper into all the Kafka terminology.
Topics
As you've seen from the C# example a Kafka Topic is like a table in a database where you save data, in Kafka case you send messages to it. You need to create a topic first and after that you have Producers sending messages to a topic and Consumers reading messages from a topic.
Topics are split in partitions. When you create a topic you need to specify how many partition but you can change this later. When a message is being sent to a topic it will be assigned to a random partition unless a key is provided.
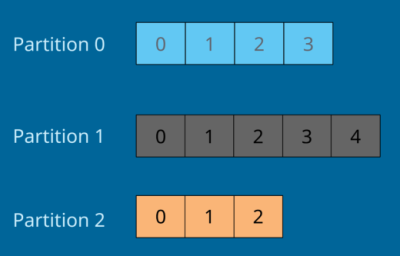
Each message in a partition gets an incremental id which is called offset. Offset has a meaning only for a specific partition. Order of a message is guaranteed only within a partition. When a message is sent to a topic that message will stored for a limited time (default is one week).
Data is immutable - you can't change it. Data is assigned randomly to a partition unless a key is provided (will explain this later).
Brokers
In the previous section I undroduced the partition but what holds the partition? It is the responsability of a Broker, or in other words a Server. A Broker is identified by an integer ID and it contains certain topic partition. Usually not all the partitions are located on the same Broker which means you need to have multiple brokers. Multiple Brokers forms a Cluster. You can have as many brokers as you want or better you need in a cluster but you usually start with three brokers. After connecting to a Broker you are coneected to the entire cluster.
Have a look at below image to understand the relationship between brokers and partitions. Let's say we have Topic 1 with three partitions, Topic 2 with two partitions and three Brokers. You can see that the partitions have been allocated to all the brokers. You can't have all three partitions, for example, in one broker only. Kafka takes care of this distribution.
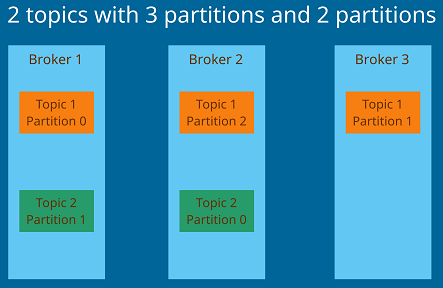
In the current setup if one cluster goes down all the partitions of that broker will not be accesable. In a distributed architecture you need to have replication.
Replication factor
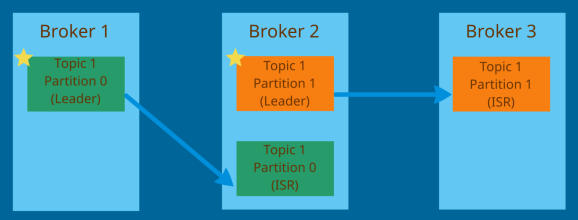
When a topic is created you need to decide about the replication factor. This means you need to tell how many copies of partitions in the topic you want to have. Early when we run a command to create a topic we provided the replication value - replication factor. A replication factor should be greater than one usually between 2 and 3.
In the below image we have Topic with replication factor 2 which means that we have two copies of each partition. If Broker 1 goes down then Broker 2 will serve the data for Topic 1 Partition 0 while Broker 1 is being restored. But how do we know which Broker will serve data for a partition? There's a notion of a Broker Leader. At any time only one Broker for a partition can be a leader. Only that broker will receive and serve the data; other brokers will synchronize the data. The brokers which are only synchronizing are called in-sync replica (ISR). Therefore, a partition can have only one leader and multiple ISR. In the image below, if Broker 1 goes down the ISR on Broker 2 will become the leader. When Broker 1 is back it will become the leader again. This decision is made by Kakfa (by Zookeeper, more on it below. We shouldn't worry about this details.
Producers
Producers will write data to topics. You don't have to specify which broker and partition you want to send the data to. You only connect to Kafka and everything happens automatically.
When Producer sends the data without a key it will be send round-robin to all the brokers in the cluster. Producers can choose to send a key with a message which can be any type. When you provide a key Kafka will send all the messages with the same key to the same partition. The reason you would want to send a key is if you want the message ordering. The message ordering is guaranteed only in the same partition.
When Producer sends a message it can chose to receive a confirmation, or acknoledgment of data writes. There are three types of acknoledgment:
- acks=0 - Producers won't wait for confirmation. It's posible to loose data
- acks=1 - Producers will wait for the leader to acknowledge. This is the default option and has limited data loss
- acks=all - Producers will wait for the leaders and replicas acknoledgment
Consumers
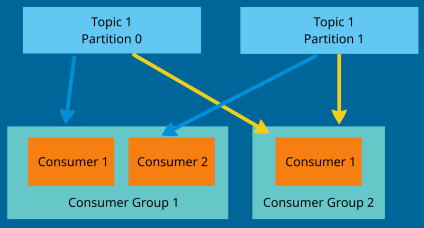
Consumers read data from a topic. Data will be read in order within each partition. If you have multiple consumers they will read the data in parallel from each partition but there's a caveat. There's a concept of Consumer Groups. You have multiple consumers and you can group them together. A consumer within a group reads from exclusive partitions. In the image below we have one Topic with two partitions and two consumers grouped in one consumer group and another consumer in its own group. You can see that consurmers from Group 1 read from both partitions but each consumer reads data from its designated partition only. In case of second consumer group, it reads from both partitions. If in Consumer Group 1 you would have a third consumer then it will be inactive because there are only two partitions to read from.
This allocation happens automatically managed by Kafka group coordinator and consumer coordinator.
Zookeeper
As you've seen in our example the first command-line we run wast to start Zookeeper. Zookeeper manages brokers and deals with all the instrumentation of a broker cluster. For example, it helps in selecting the leader of partitition, sends notification to Kafka when changes happen (new topic created, broker is down, etc.). In the latest versions Zookeeper is completely isolated from consumers and producers.